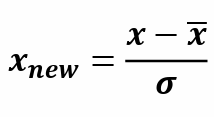데이터 수집 및 전환 1. 데이터 수집★ 데이터 유형에 따른 빅데이터 수집기법(★) - 종류 꼭 기억해두기!1. 정형데이터2. 반정형데이터3. 비정형데이터 2. 데이터 변환- ETL : DW, DM에 저장하기 위해 Extract(추출), Transform(변환), Load(적재) 하는 기술 데이터 이동 및 변환이 주 목적임 3. 데이터 비식별화- 5가지 처리기법 및 예시까지 외우기!(★) 4. 데이터 품질검증정형데이터의 품질기준(5가지 암기!)1. 완전성 : 데이터 누락이 없어야 함2. 유일성 : 데이터 중복이 없어야 함3. 유효성 : 정해진 데이터 범위 혹은 도메인을 만족해야 함4. 일관성 : 데이터 구조, 형태가 일관되어야 함5. 정확성 : 실제 객체의 표현값을 정확히 반영해야..