분석 변수 처리
3. 파생변수
1 파생변수 : 분석가가 주관적으로 만든 변수(의미부여) -> 주관적으로 만든 변수이기 때문에 논리적으로 타당해야 함
2 요약변수 : 합계, 횟수, 빈도 등의 기본적인 요약 변수, 많은 모델에서 공통으로 사용할 수 있어 재활용성이 높음
4. 변수변환
1 변수의 구간화 : 연속형 변수를 다수의 구간으로 나눔(구간=변수가 된다)
- ex) 점수 70~100점 -> 1등급 : 90~100점
2등급 : 80~89점
3등급 : 70~79점
2 더미변수(Dummy Variable)

3 원-핫 인코딩(One-Hot Encoding)

범주형 변수 변환방법으로 k개의 범주가 있을 때 더미변수는 k-1개로, 원핫인코딩은 k개의 변수로 바꿔준다.
4 정규분포화
- 로그변환 : 데이터에 로그를 취해서 정규분포에 가깝게 만들어준다.
(정규분포를 가정하는 분석을 진행할 때 사용)

5. 불균형데이터(Data Imbalance) = Class 불균형 = 종속변수(Y) 불균형
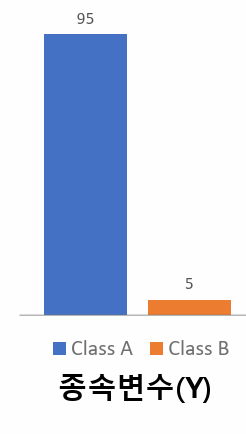
설명
- 지도학습의 분류(Classification)에서 발생하는 문제로 각 집단(Class)에 속하는 데이터의 숫자가 차이가 많이 나는 경우를 말함
문제점
- 모델이 전부 Class A라고 분류해도 정확도(Accuracy)는 95%로 높음, 모델을 신뢰할 수가 없음
-> 데이터 불균형 문제가 있을 때 정확도(Accuracy)로 판단하면 안된다! 주로 F1 score 사용
불균형데이터 해결방법
오버샘플링(Over Sampling)
: 소수의 Class를 더 많이
- 방법 : 단순복사, SMOTE 계열 방법
- 단점 : 과적합 문제 발생 가능
언더샘플링(Under Sampling)
: 다수의 Class를 적게
- 방법 : 랜덤추출, 토멕링크, CNN, OSS
- 단점 : 정보손실(모델성능 ↓ 가능성)
Weight balancing
: Class 비중별로 가중치를 두는 것

#참고
CNN(Condensed Nearest Neighbor) - 언더샘플링 방법
- 숫자가 더 많은 Class에서 데이터를 제거할 때, 밀집된 데이터를 제거해서 남은 데이터는 해당 Class의 대표성을 가지게 샘플링 하는 방법
준지도 학습(Semi-Supervised Learning)
- 한 범주는 목표값(Y)이 표시되게, 다른 범주는 목표값 없이 학습하는 방법, 특정 Class만 학습하는 방법
'[데이터자격시험용-필수요약정리]' 카테고리의 다른 글
| 빅데이터 분석기획 - 데이터 분석 계획 (0) | 2024.04.02 |
|---|---|
| 빅데이터 분석기획 - 빅데이터의 이해 (0) | 2024.04.02 |
| 빅데이터 탐색 - 데이터전처리(차원축소/피처 추출방법) (0) | 2024.04.01 |
| 빅데이터 탐색 - 데이터전처리(데이터축소변환/분석변수처리) (0) | 2024.04.01 |
| 빅데이터 탐색 - 데이터전처리(이상값 처리방법) (0) | 2024.04.01 |