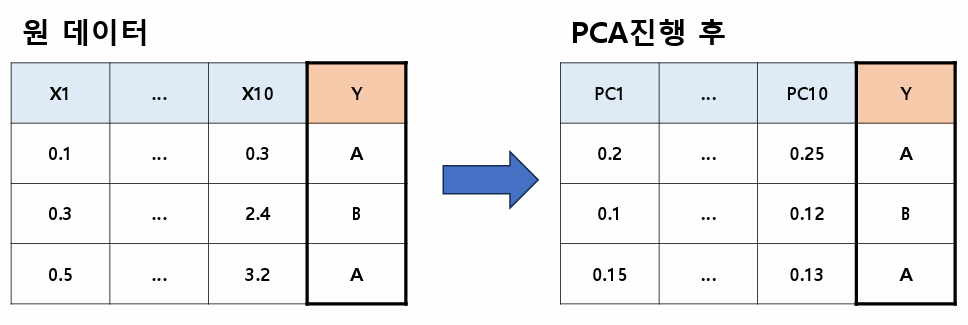
다변량 분석 주성분 분석(PCA, Principle Component Analysis)- 다수의 변수를 소수의 변수로 줄여준다(단, 해석은 어려움) -> 서로 상관성이 높은 변수들의 선형 결합을 통해- 소수의 변수는 서로 상관성이 없음(서로독립, 상관계수=0, 다중공선성 존재X)- 각 변수들의 분산값 총합을 총 변동이라고 하며, 각 주성분들마다 기여하는 정도를 기여율이라고 함 -> 누적 기여율이 85%가 넘어갈 때의 주성분 수를 결정함(첫 번째 주성분이 제일 기여율 높음) 스크리 산점도(Scree plot)- 주성분 분석에서는 기울기가 급격히 변하는 곳에서 -1을 한다- 3에서 기울기가 급격히 변하므로 적절한 주성분의 수는 3-1=2이다(2개의 변수만 선택, PC1과 PC2) 시계열 분석1. 정상성..