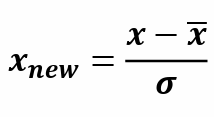2. 차원축소 : 변수의 개수를 줄여서 새로운 차원의 데이터를 생성 * 선형모델(회귀분석 등) 변수의 개수가 많을 경우 다중공선성 발생 -> 차원축소가 하나의 해결책 1 피처선택(Feature Selection) = 변수선택 - 여러 변수들 중에 학습에 중요한 변수를 찾아 선택하는 것 2 피처추출(Feature Extraction) = 변수추출 - 기존 변수들 간의 관계를 파악해서 선형 or 비선형 결합을 통해 새로운 변수를 생성 피처추출(Feature Extraction) 방법다차원 척도법(MDS, Multidimensional scaling)- 개체들 사이의 유사성을 기준으로 2차원, 3차원으로 시각화 주성분 분석(PCA)- 변수의 선형 결합을 통해 데이터를 잘 표현할 수..