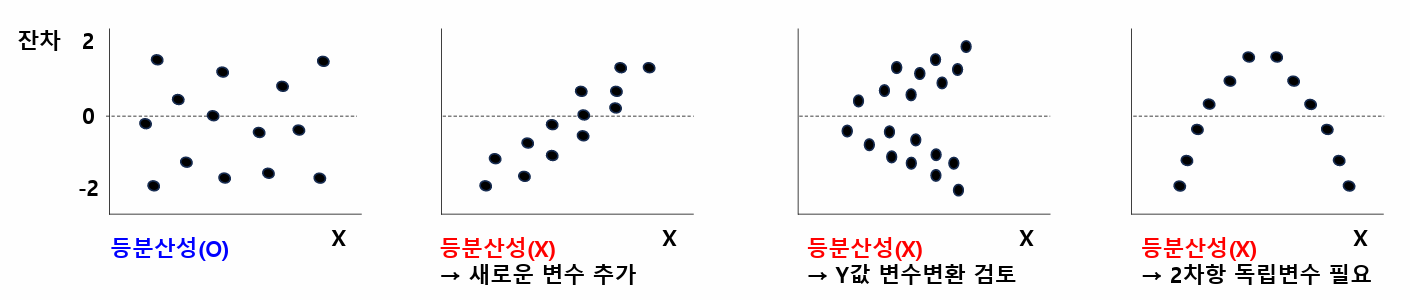
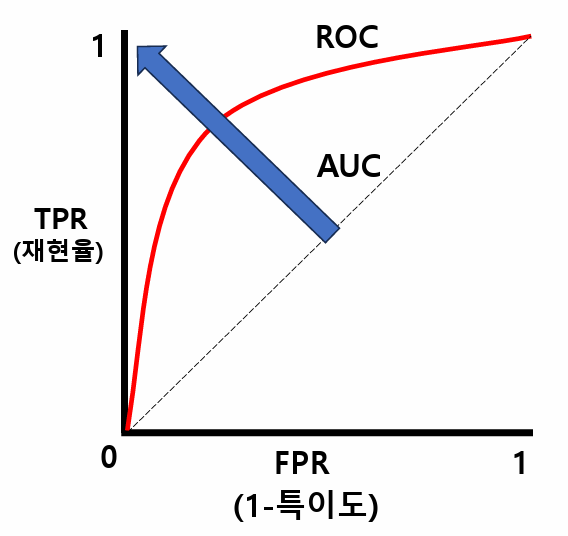
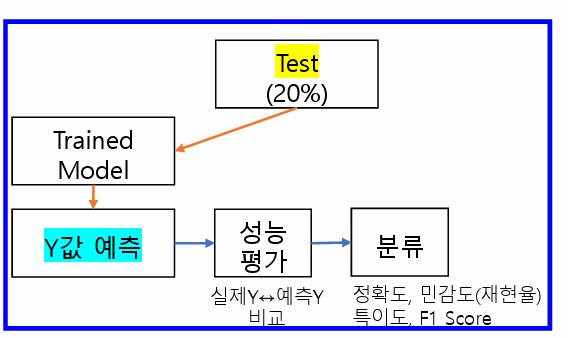
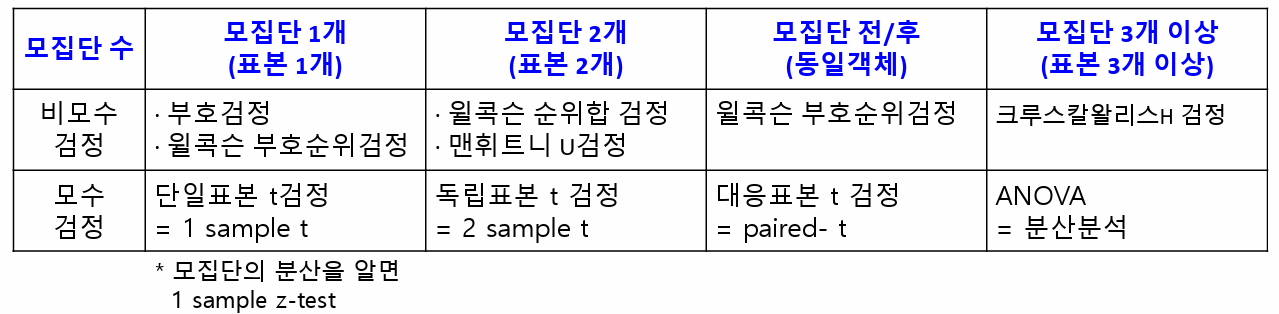
회귀모형 진단 1. 회귀모형에 대한 진단- 회귀모형 : F검정, p-value가 0.05보다 작아야 함(유의확률 H0(귀무가설) : 회귀계수(𝛽i) 는 0이다- 회귀계수 : t검정, p-value가 0.05보다 작아야 함(유의확률 H0(귀무가설) : i번째 회귀계수는 0이다 2. 잔차에 대한 가정 : 정규성 / 등분산성 / 독립성[잔차의 등분산성 예시] - 잔차에 대해서 산점도로 그려봤을때 X에 따라서 분산이 경향을 띄는 것이 아니라 0을 기준으로 위아래로 고르게 분포되어 있는 것 복습) 회귀분석의 가정1. 선형성 : 독립변수(X)와 종속변수(Y)간의 선형성2. 잔차의 3가지 가정(등분산성, 정규성, 독립성) a. 등분산성 : 산점도 b. 정규성 - H0(귀무가설) : 정규분포..