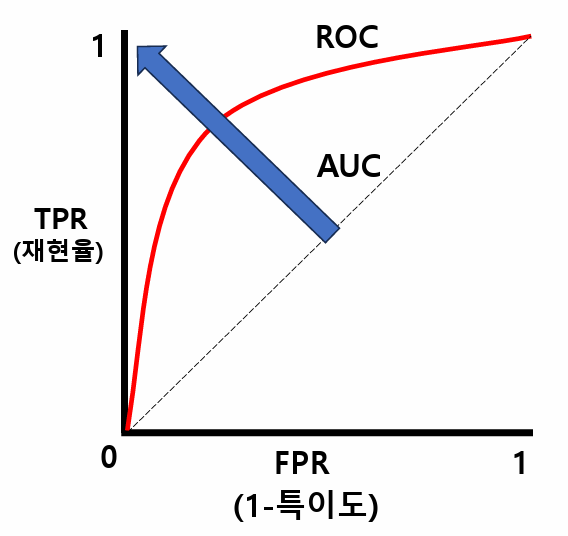
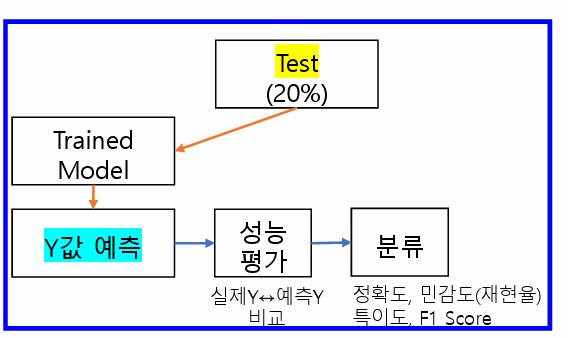
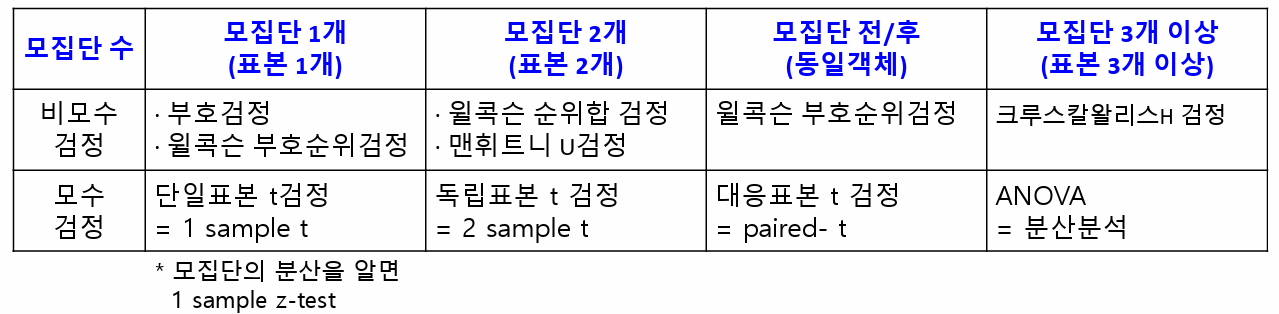
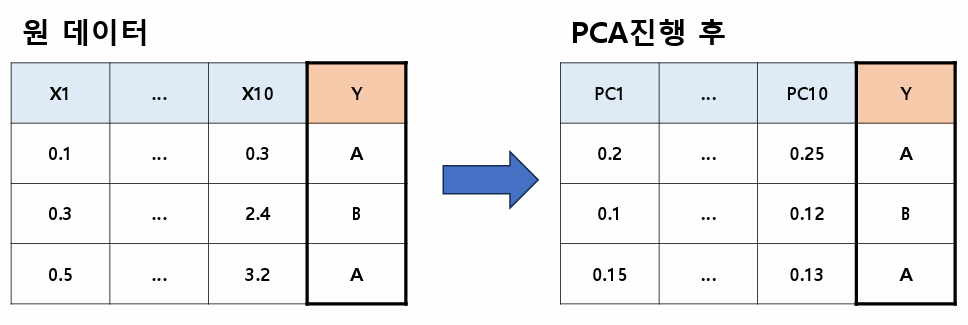
ROC curve AUC(Area Under the Curve): ROC 커브의 아래쪽 면적을 뜻함0.5~1.0 값을 가지며 1로 갈수록 분류성능이 좋음0.9~1.0 : 뛰어남(Excellent)0.8~0.9 : 우수함(Good)0.7~0.8 : 보통(Fair)0.6~0.7 : 불량(Poor)0.5~0.6 : 실패(Fail) #가장 이상적인 ROC 커브는 민감도1, 특이도1인 점을 지난다.# x축은 거짓긍정률 : FPR(False Positive Rate) = 1-특이도# y축은 참긍정률 : TPR(True Positive Rate) = 민감도(Sensitivity) = 재현율(Recall)