분류성능
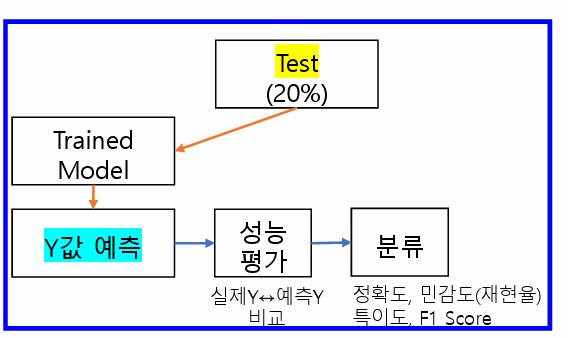

이진분류(0 or 1)에서 나올 수 있는 경우의 수 : 4가지
혼동행렬(Confusion matrix)

TP : True Positive (예측 Positive, 실제 Positive)
FP : False Positive (예측 Positive, 실제 Negative)
TN : True Negative (예측 Negative, 실제 Negative)
FN : False Negative (예측 Negative, 실제 Positive)
★Tips!
1. 예측/실제, Positive/Negative 위치 확인
2. 예측기준으로 4가지(TP,TN,FP,FN) 항목 위치 표기
3. 각각의 지표 정의 그대로 계산하기
여러가지 지표들! 정의를 암기할 것!
1. 정확도(Accuracy) : 전체 중에 잘 분류한 비율 (TP+TN) / 전체
2. 민감도(Sensitivity) : 실제 Positive 중에 잘 분류한 비율 TP / (TP+FN)
=재현율(Recall)
3. 특이도(Specificity) : 실제 Negative 중에 잘 분류한 비율 TN / (FP+TN)
4. 정밀도(Precision) : 예측 Positive 중에 잘 분류한 비율 TP / (TP+FP)
5. F1 score = 2*정밀도*재현율 / (정밀도+재현율)
# 분석하려는 과제들마다 보는 지표들이 다름. Positive와 Negative가 불균형 되어있으면(불균형 데이터셋) 정확도만 보면 안됨.
# 민감도 = 재현율 = TPR(True Positive Rate), 정밀도 = PPV(Positive Predicted Value)
'[데이터자격시험용-필수요약정리]' 카테고리의 다른 글
| 빅데이터 결과해석 - 분석모형평가(군집분석 및 기타 성능지표) (1) | 2024.03.23 |
|---|---|
| 빅데이터 결과해석 - 분석모형평가(분류성능 ROC curve) (0) | 2024.03.23 |
| 빅데이터 결과해석 - 분석모형평가(회귀성능) (1) | 2024.03.23 |
| 빅데이터 모델링 - 분석기법적용(비모수통계) (0) | 2024.03.17 |
| 빅데이터 모델링 - 분석기법적용 (다변량분석/시계열분석) (2) | 2024.03.17 |