LOD Expressions 1. Include :
VLOD에 포함되지 않은 특정 차원을 포함하고 싶을 때


Include 표현식을 화면 안으로 집어넣어 보자.

어떻게 나온 결과일까?
Include 표현식을 화면에 넣으면, 눈에 보이지는 않지만 태블로 뒷단에서
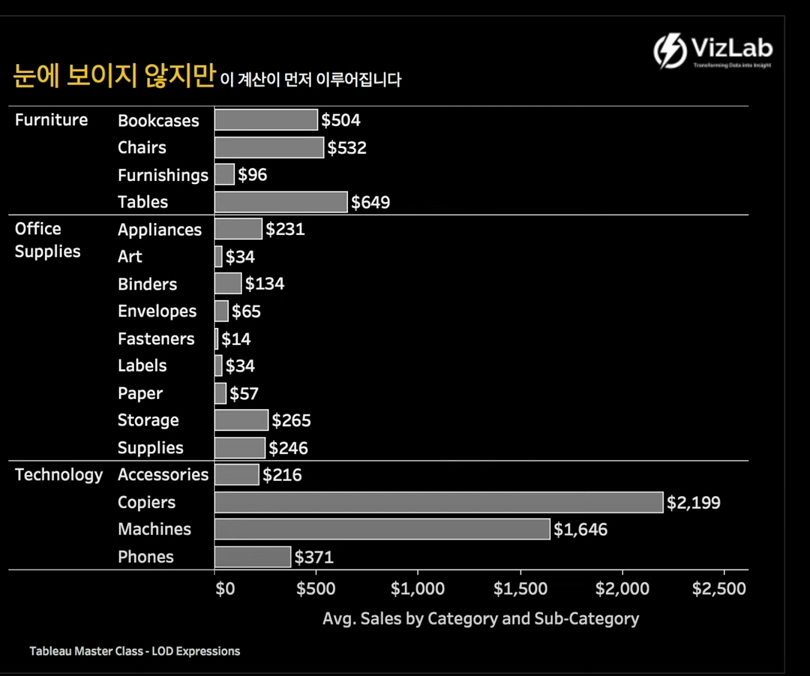
이 계산이 먼저 이루어진다.
준비 화면의 VLOD는 카테고리 수준 한정 평균 매출값이 보여지고 있지만,
Include 표현식을 안에 집어넣는 순간
현재의 VLOD 레벨에서 서브카테고리로 세분화된 그 레벨에서 평균 Sales 계산이 먼저 이루어지는 것이다.

다음으로 그 결과를 가지고 카테고리를 기준으로 다시 계산이 이루어지는 것이다.
카테고리를 기준으로 기존의 결과들(1차 계산 결과(서브카테고리 별 평균))이 재집계되는 것이다.

다시 말해, 1781은(=result 이미지의 1760) Bookcases의 평균(504), Chairs의 평균(532), Furnishings의 평균(96), Tables의 평균(649)의 합산으로 나온 결과이다.
그럼, 왜 재계산이 이루어질까?
Include LOD는 태생적으로 어떤 새로운 차원을 포함하고 있기 때문에 Include LOD에서 만든 그 결과는 VLOD보다 뎁스가 깊을 수 밖에 없다.
그 깊은 레벨에서 계산된 결과를 그거보다 얕은 VLOD 레벨에서 표현해야 되기 때문에 반드시 두번째 계산이 이루어질 수 밖에 없는 것이다.
Include LOD의 집계를 평균으로 바꾼 후 죄측과 우측을 비교해보자.

좌측 : 카테고리 별로 매출을 더한다. -> 각 매출을 각 카테고리 행의 개수로 나눈다. SUM([Sales]) / SUM([Number of Records])
우측 : 서브카테고리 별로 매출을 더한다. -> 각 매출을 각 서브카테고리의 행의 개수로 나눈다. -> 카테고리별로 각 서브카테고리 별 평균 매출을 다시 더한다. -> 각 매출을 각 카테고리의 서브카테고리 개수로 나눈다.
먼저 서브카테고리 레벨에서, SUM([Sales]) / SUM([Number of Records]) (= Avg. Sales by Sub-Category)
다시 카테고리 레벨에서, SUM([Avg. Sales by Sub-Category]) / COUNTD([Sub-Category])
평균의 평균을 구하는 셈.
LOD Expressions 1. Include 핵심정리!
Include LOD에 명시된 차원을 포함해서 집계가 이루어짐(첫번째 계산)
VLOD에 맞추어 표현하기 위해 첫번째 계산 결과를 재집계함(두번째 계산)
LOD Expressions 1. Include 연습
각 도시(City)별 평균 매출(Sales)을 기준으로 최대-최소 편차가 다섯번째로 큰 주(State)는 어디인가요?

최종적으로 뽑아내야 할 결과는 도시 레벨에서의 평균을 가지고 작업을 하는 것이다.

City 차원을 마크 카드 원으로 표시해보자. 점 하나 하나가 각 주에 소속되어있는 도시들인 것을 알 것이다.
Alabama 주를 보면 도시인 Mobile과 Tuscaloosa의 평균 매출이 각각 최대값과 최소값인 것을 확인할 수 있다.
다시 돌아와서 계산된 필드를 생성.

City 레벨을 포함 -> Sales는 평균으로 본다.
이 계산된 필드를 화면에 집어넣는다면,
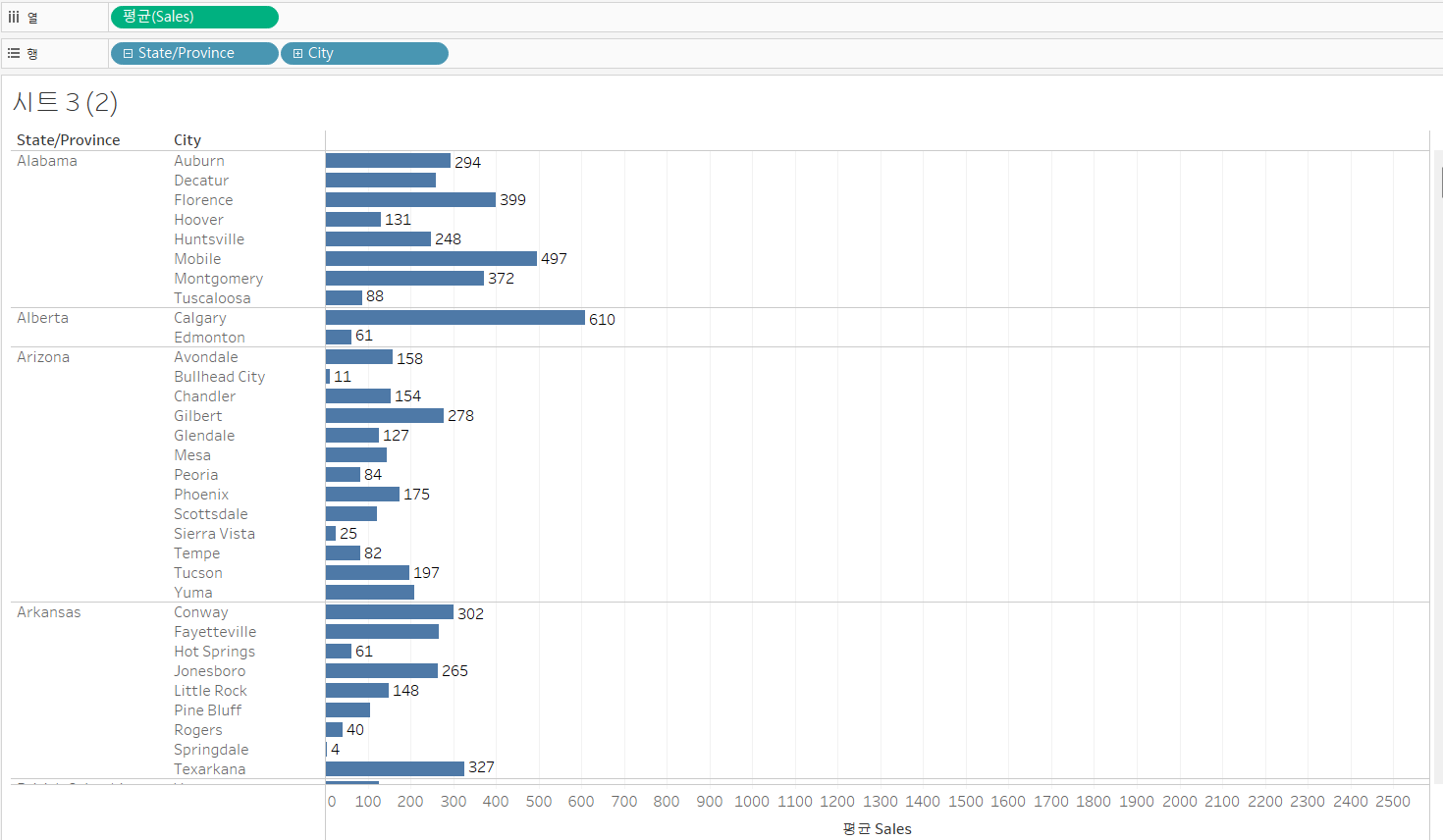
이런 계산이 뒷단에서 1차적으로 이루어질 것이다. (City 레벨을 포함해서 평균 매출을 구함.)
1차 집계된 결과를 어떻게 다시 한 번 집계해야 할까?

Include LOD 표현식의 집계결과를 최대값과 최소값으로 바꿔준다.
위의 원(주 별 최대 값(City 별로 Sales의 평균을 구한 것들 중에서 평균 값이 가장 큰 City) = Alabama 주의 경우 Mobile)
아래 원(주 별 최소 값(City 별로 Sales의 평균을 구한 것들 중에서 평균 값이 가장 작은 City) = Alabama 주의 경우 Tuscaloosa)
위의 원에서 아래 원을 빼서 편차를 구해야 한다.

한 축으로 합치면,


행 선반의 측정값을 복제하여 측정값2 를 라인 모양으로 바꾼다.

측정값 이름 을 경로에 한 번 더 넣어준다.


이중축 -> 축 동기화

화면에서 편차가 만들어졌다.
이 화면을 내림차순으로 정렬해야 한다.

계산된 필드를 만들어준다.(※ 참고 : 타이핑 하지 말고 넣고자 하는 필드를 드래그 드랍하면 됨.)

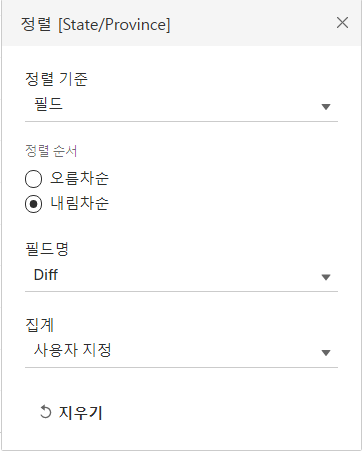
State -> 정렬 -> 정렬 기준(필드) -> 필드명(Diff) -> 내림차순

편차가 가장 큰 주는 뉴욕주이다.
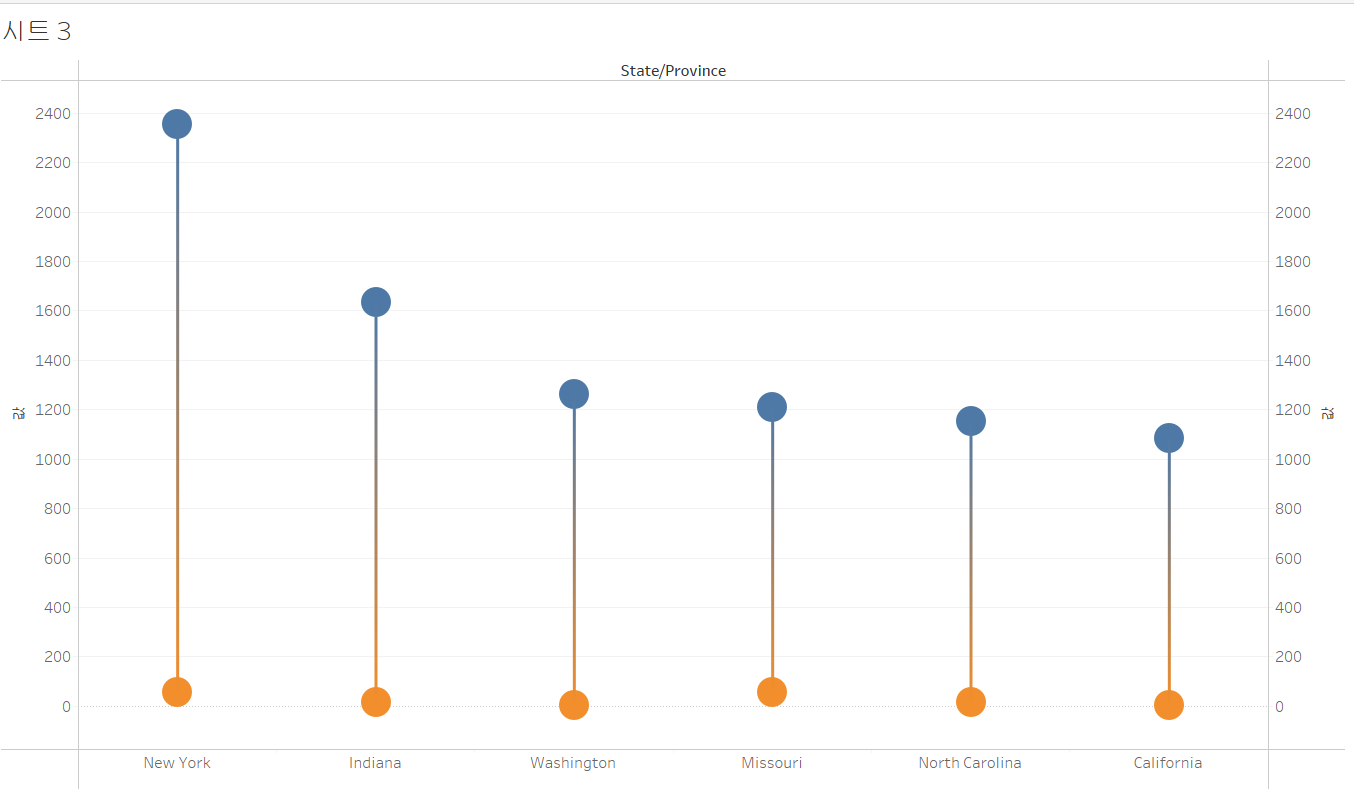
결론 : LOD 표현식을 사용하여 더 낮은 레벨에서 계산된 결과를 가지고 더 높은 레벨에서 정렬을 하거나 값을 구할 수 있다.
Include LOD 표현식은 언제 활용할 수 있나요?
: 일단 데이터셋의 뎁스가 상대적으로 깊어야 한다. 집계를 두 번 해야만 할 때!(평균의 최대값, 최소값의 평균 등),
재집계(두번째 계산)가 SUM이 아닌 다른 집계값이라면(AVG 등) 고려 가능
공부내용 :
https://www.inflearn.com/course/%ED%83%9C%EB%B8%94%EB%A1%9C-%EC%A4%91%EA%B8%89
[지금 무료]태블로 레벨UP 강의 | VizLab - 인프런
VizLab | , 🗒 강의소개 강의를 만들게된 계기가 어떻게 되시나요? 왜 이 강의를 만들게 되신거죠?저는 2015년 말에 태블로라는 툴을 처음 접하게 되었습니다. 당시에도 한국에 태블로가 소개되지
www.inflearn.com
'[Tableau]' 카테고리의 다른 글
| EXCLUDE LOD 표현식 (2) (0) | 2025.03.18 |
|---|---|
| EXCLUDE LOD 표현식 (1) (0) | 2025.03.17 |
| VLOD (View Level of Detail) (0) | 2025.03.10 |
| WINDOW 함수 (0) | 2025.03.07 |
| 테이블 계산 주요 함수 - INDEX, SIZE, RANK, TOTAL (0) | 2025.03.06 |